

Let’s continue the blog series on VMware Enterprise PKS and NSX-T, this time we’re going to deploy a multi-tier application to the PKS K8S Cluster. We will deploy an Enterprise grade version of Kafka from Confluent along with the Confluent platform components.
Apache Kafka is built around an open-source project. It is used in real-time data streaming architectures and provides a fast, scalable, durable and fault-tolerant messaging system which works in a publish-subscribe model. Kafka provides better throughput, reliability, and replication characteristics compared with other messaging systems like RabbitMQ, JMS etc. Confluent offers the Enterprise production-grade version of Kafka (Confluent Kafka Enterprise) and provides provides additional offerings on top of the Opensource bits called the Confluent Platform. Below are the components of Confluent Platform:
- Kafka Brokers – This is the core component of the Confluent Platform. They form the data persistency and storage tier of Kafka
- Kafka Java Client APIs – They include Producer API, Consumer API, Connect API and Streams API
- Zookeeper – Used by the Broker cluster as a distributed state management and quorum.
- Kafka Connectors – Used for integrating with external systems using Connect APIs.
- Confluent Control Center – Provides a GUI for managing and monitoring Kafka.
- Confluent Replicator – Managing replication of data and topic configuration between multiple data centers
- Confluent Auto Data Balancer – Balances the data in topic partitions across the broker cluster during normal operations and scale out scenarios.
- Confluent Schema Registry – Provide support of messages in AVRO format.
- Confluent MQTT Proxy – Provides bidirectional access to Kafka from MQTT devices and gateways without the need for a MQTT Broker in the middle.
- Confluent REST Proxy – Enables publishing and subscribing to messages using a REST API interface.
- Confluent KSQL – Provides an interactive SQL interface for stream processing on Kafka.
In this blog post, we will deploy Confluent Platform on a PKS Kubernetes cluster with NSX-T Networking using Confluent Operator. We will leverage the same infrastructure that we used in the earlier article.
https://vxplanet.com/2020/02/28/nsx-t-shared-tier-1-architecture-in-vmware-enterprise-pks/
Let’s get started.
Logical Architecture
The architecture is same as the one used in my previous articles, please visit:
https://vxplanet.com/2020/02/28/nsx-t-shared-tier-1-architecture-in-vmware-enterprise-pks/
Admin VM for PKS Management
The deployment and management of Enterprise PKS platform is done via an Admin VM running RHEL7.5. It is deployed on the same Overlay subnet as PKS Management. It has the ‘pks’ and ‘kubectl’ utilities installed along with all necessary binaries to deploy the Confluent Platform. Confluent Operator is downloaded and extracted to a directory /confluent. Confluent CLI is downloaded and extracted to /confluent/confluent-5.4.0/

More details on Confluent Operator and download instructions are available in the Confluent documentation page below:
https://docs.confluent.io/current/installation/operator/co-deployment.html
Helm 3 is needed on the Admin VM for Confluent Operator deployment and can be installed using the below link:
https://helm.sh/docs/intro/install/
![]()
Configuring the default Provider YAML configuration file
The Provider YAML configuration file need to be updated with deployment inputs. Specify the Availability zones, Storage Class (Provisioners), Sizing of components, Loadbalancer req, License, image registry, domain and other platform options. For Enterprise PKS, the YAML to be edited is /confluent/helm/providers/private.yaml
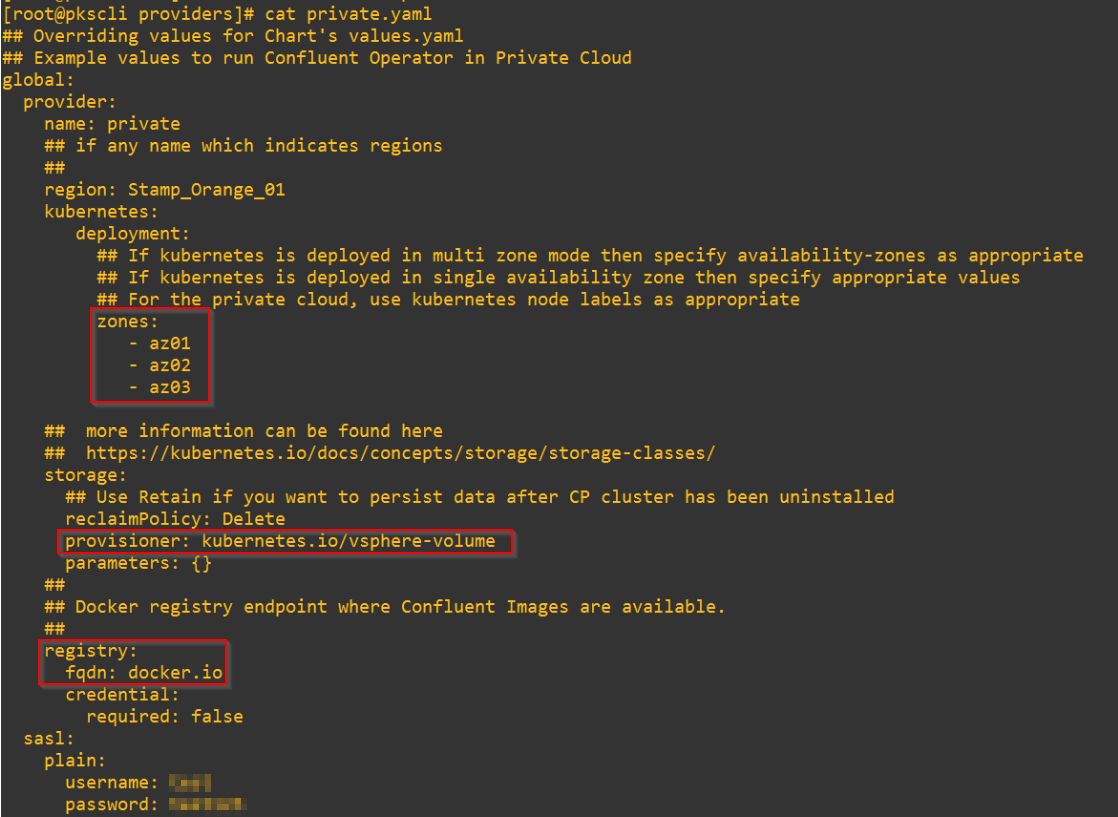
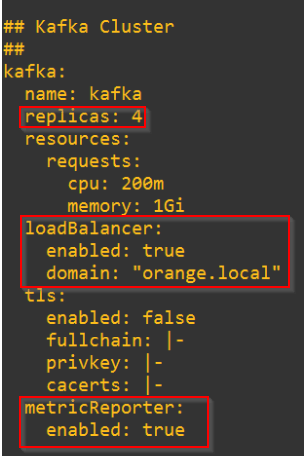
Update the values against each Platform component. For anything, that requires an Ingress access, set “Loadbalancer” to “True”.
This version of PKS uses the default in-tree vSphere provisioner, but if we use a CSI external provisioner, input the necessary settings under ‘Parameters’.
Creating the namespace for Confluent Platform components
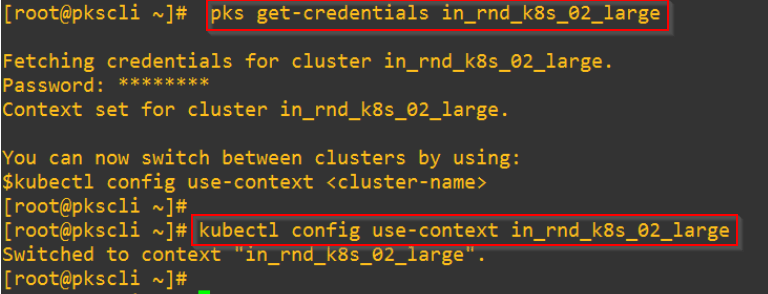
We will use the PKS K8S cluster “in_rnd_k8s_02_large”, which is created with a ‘Large’ plan.

This cluster uses a ‘Shared Tier1 Topology’ and uses ‘Medium’ Loadbalancer. The POD network is non-routable and a NAT instance is used for outbound access.

Let’s connect to the K8S context and create a namespace called ‘confluentplatform’.

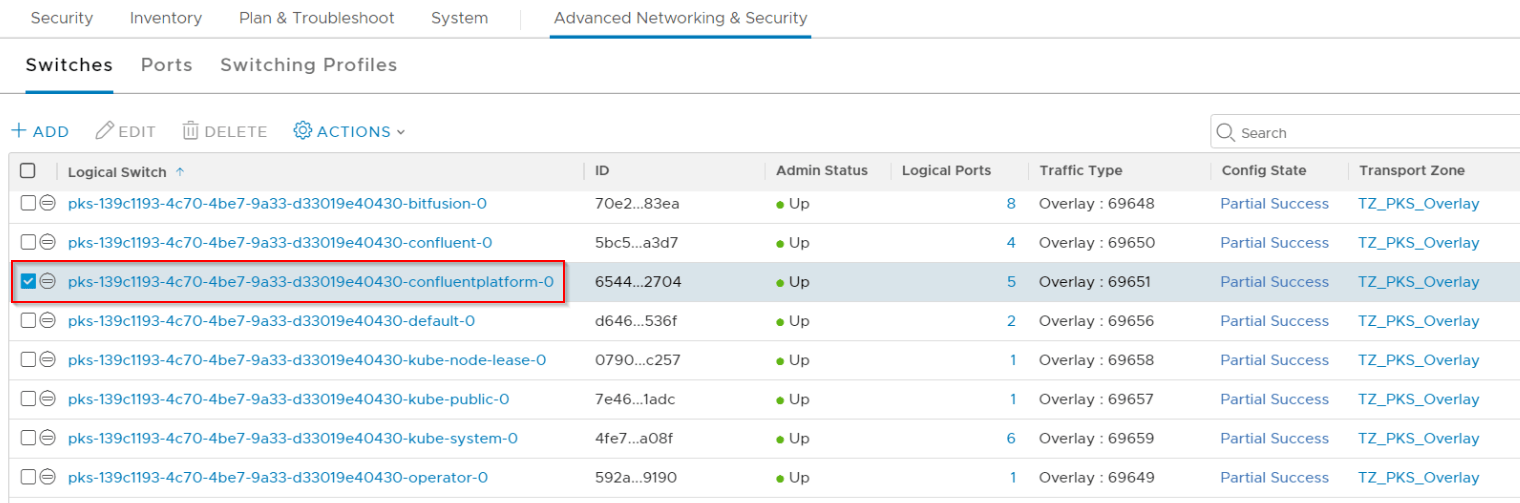
A new NSX-T Logical Segment is created for this namespace and is attached to the Shared Tier 1 Gateway for the Kubernetes Cluster.
An SNAT rule is also created for the logical Segment for outbound access. The translated IP is taken from the Floating Pool already defined in NSX-T

Deploying the Confluent Operator POD
Deployment of the Operator POD and other Platform Components are done based on the instructions in Confluent documentation: https://docs.confluent.io/current/installation/operator/co-deployment.html

Verify that the Operator POD is running and that Custom Resource Definitions (CRD) are created.

A service account called “cc-operator” and ClusterRoles and Bindings are created.

Deploying the Zookeeper Ensemble

3 X Zookeeper Ensemble is deployed over the three availability zones defined in the provider yaml config. Persistent volumes are dynamically provisioned for database and transaction logs on the shared NFS volume.

PVs are provisioned as vmdk files on the NFS datastore.

Deploying the Kafka Broker Cluster
We will deploy a 4 node broker cluster across the Availability Zones.
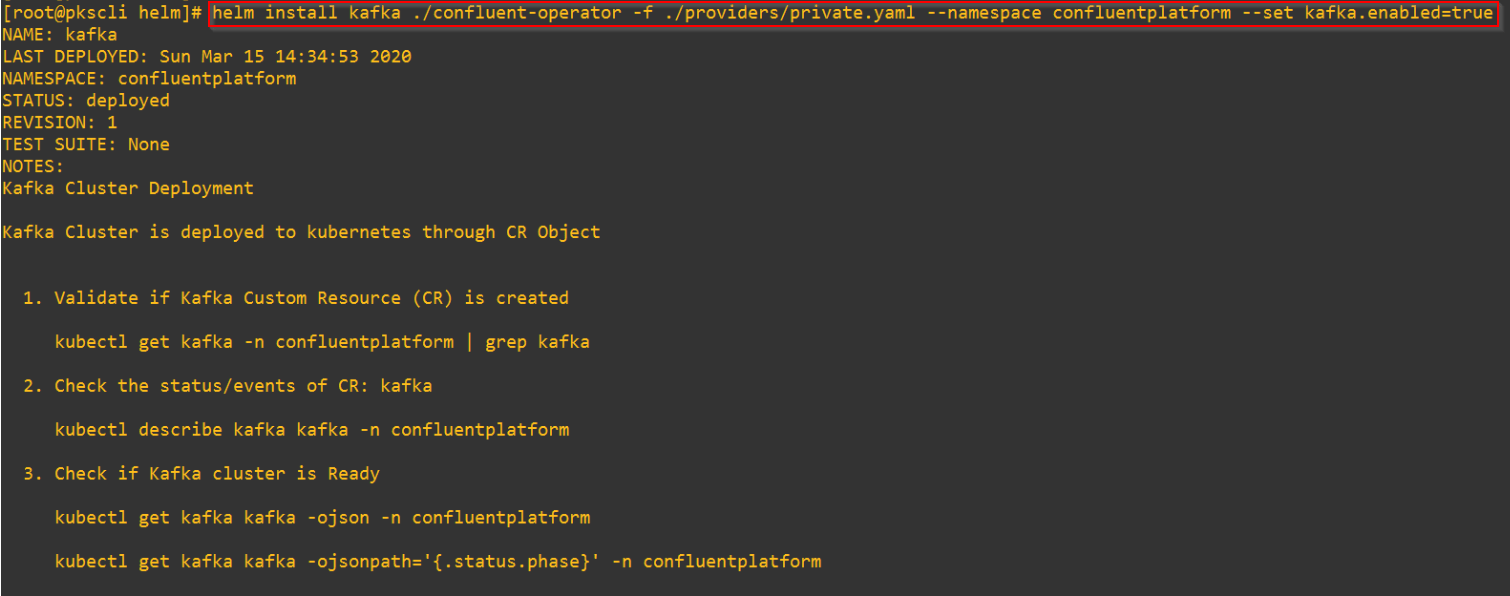

A Loadbalancer Service is instantiated as front-end for ingress access to the broker cluster.

We should see this as a new Virtual Server (VIP) on the Tier 1 Loadbalancer which was already deployed during cluster creation.

For each Broker POD, we should add DNS records on our external DNS pointing to the LB VIP to allow Kafka Producer and Consumer access to the Broker cluster.

Persistent Volumes are dynamically created on the NFS datastore for Broker Log Storage.
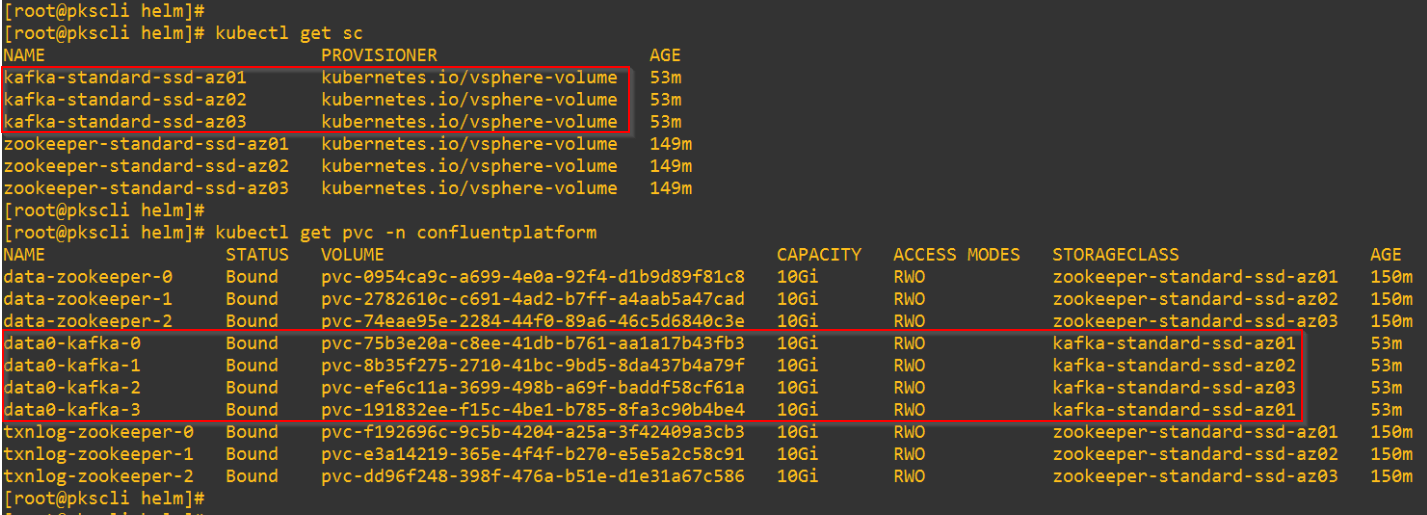
PVs are provisioned as vmdk files on the NFS datastore.

Now we have the Confluent Operator, Zookeeper Ensemble and Kafka Broker Cluster deployed. We will continue in Part 2 to deploy rest of the Platform Components followed by a quick publish-subscribe validation.
I hope the article was informative.
Thanks for reading
Interested to read further? Here is the other part of the series:
