

We are now at Part 2 of Using NSX-T Loadbalancer for the NSX-T Management cluster. If you have missed Part 1, here is the link:
https://vxplanet.com/2020/03/26/using-nsx-t-loadbalancer-for-the-nsx-t-management-cluster-part-1/
Let’s continue
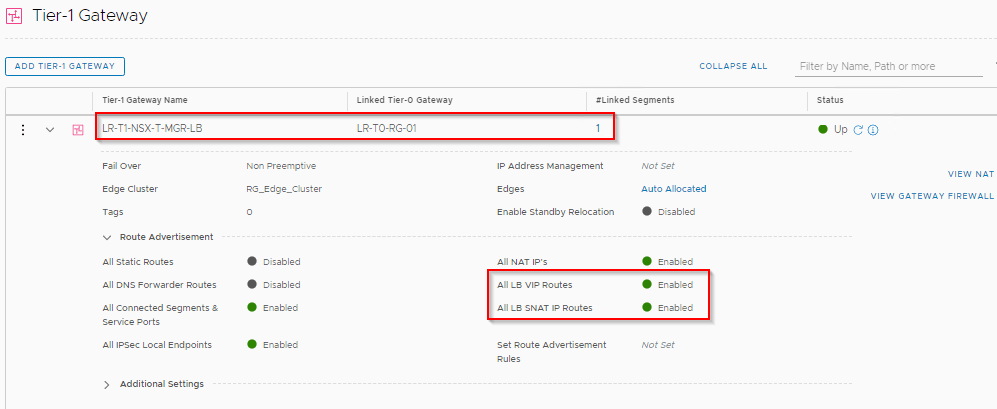
Creating Tier 1 Gateway for the NSX-T Management Cluster
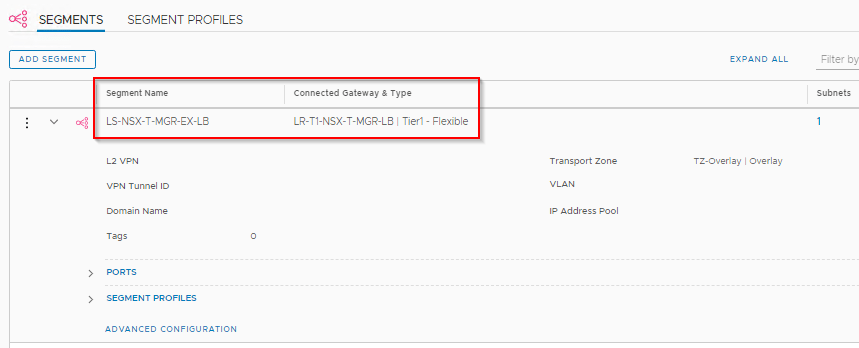
The Tier 1 Gateway (LR-T1-NSX-T-MGR-LB) need to be instantiated on the Edge Cluster as it need to support a Loadbalancer Service. Route Advertisement for the LB VIP and SNAT is also configured, so that once a VIP is created it will be seen by the Leaf Switches. The Tier 1 gateway is linked to the upstream Tier 0 Gateway.
Deploying the Loadbalancer
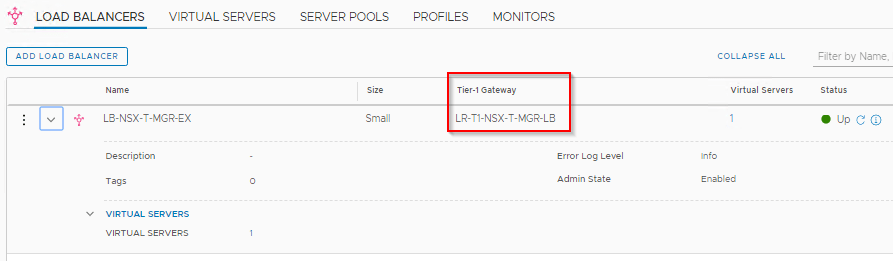
For this work, a Loadbalancer with Small formfactor is deployed on the Tier 1 Gateway , LR-T1-NSX-T-MGR-LB.
Creating the Virtual Server
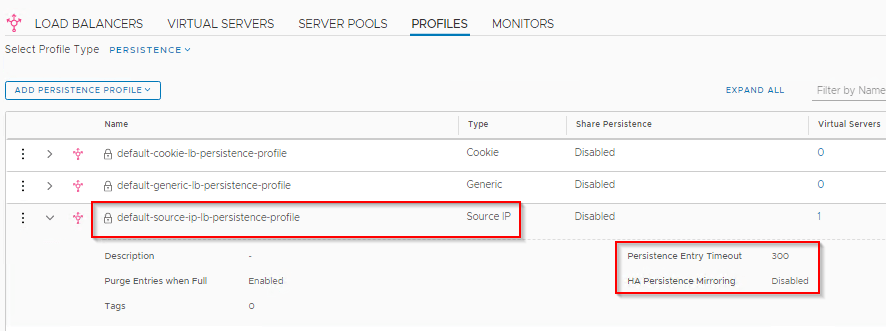
A Layer4 VS “VS-NSX-T-MGR” with IP 192.168.115.254 and listening on port 443 is created. This will be advertised by the T0 BGP process to the customer networks. We have attached a Source IP Persistence Profile to achieve stickiness between clients and the Real Servers. The Real Servers are the NSX-T manager instances. The choice of Persistence profile depends upon the infrastructure. For eg, if all the client requests come from a NAT’ed IP, then Source IP Persistence does no difference than a Cluster VIP.
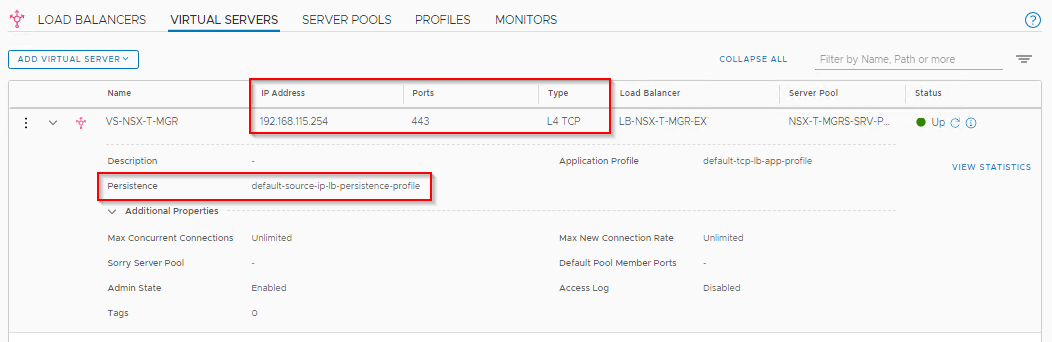
Persistence Timeout is chosen to be the default 300s. Optionally Enable “HA Persistence Mirroring” if the persistence tables need to be in sync between the Active and Standby Edge nodes, so that the tables can be preserved in case of Edge node failover.
Creating the Server Pool
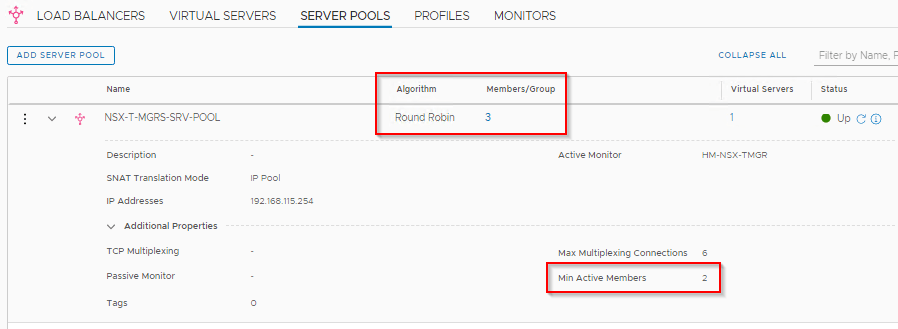
The Server pool has all the three NSX-T Manager instances as Real Servers. Round Robin is used as the Scheduling algorithm. We’ve also set the minimum Active members to 2, so that a quorum is maintained. A health monitor is also configured to continuously poll the NSX-T manager instances for their availability and dynamically take out of the pool, if found unhealthy.
Configuring the Health Monitor
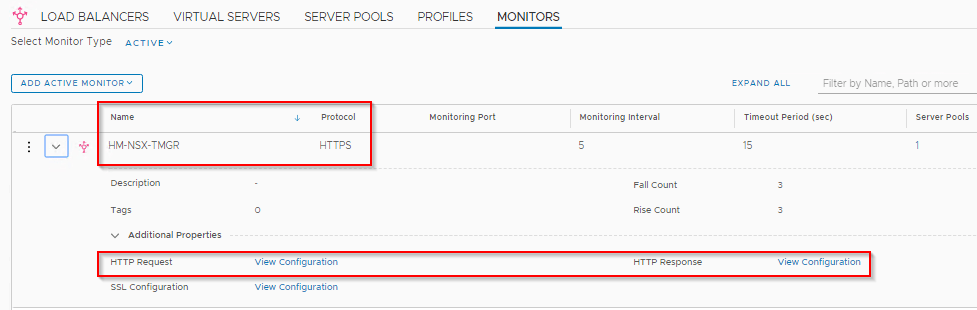
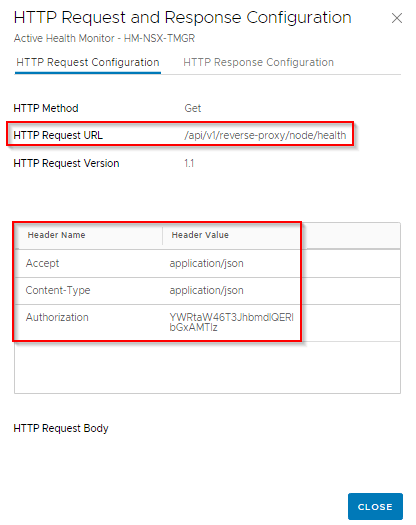
The health monitor is configured for port 443 and places an HTTPS request with the below header information:
- Request URL : /api/v1/reverse-proxy/node/health
- Authorization : A base64 encoded value of Username and password. This can be generated from www.base64encode.org
- Content-Type : application/json
- Accept : application/json
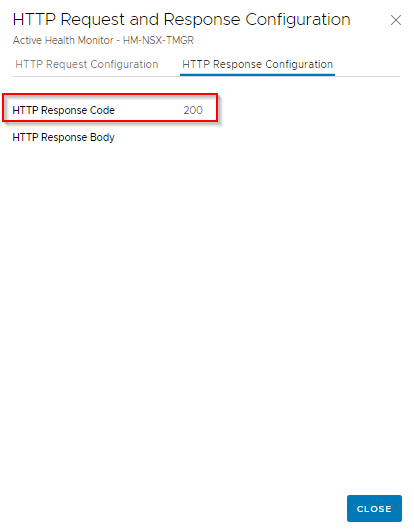
- Response Code : 200
At this moment, we are done with the Loadbalancer configuration and we should be able to access the NSX-T Management Cluster using the LB VIP.
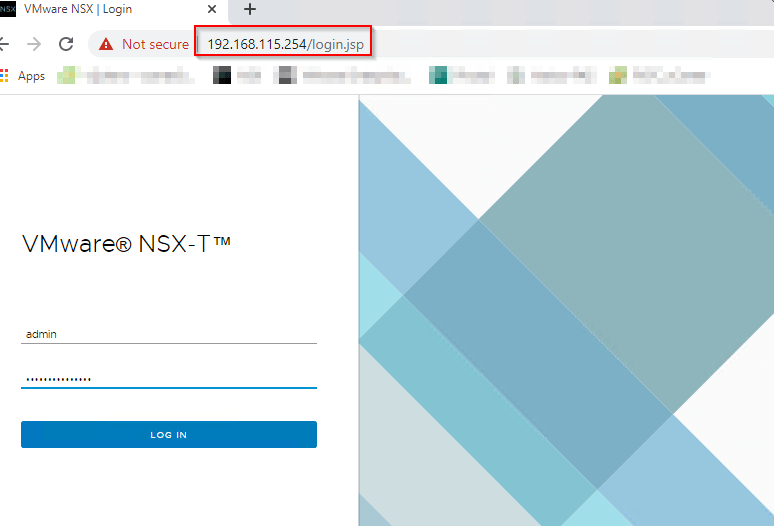
Optionally, we could add a DNS entry for the NSX-T Management Cluster pointing to the LB VIP.
Statistics
WebUI gives statistics about the VS, Server Pools and the Loadbalancer service.
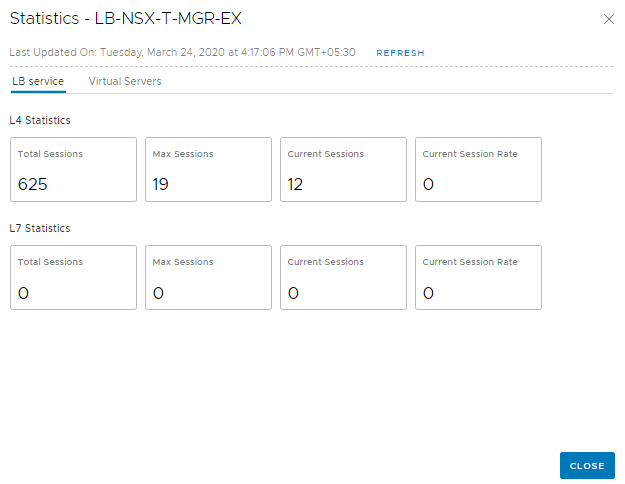
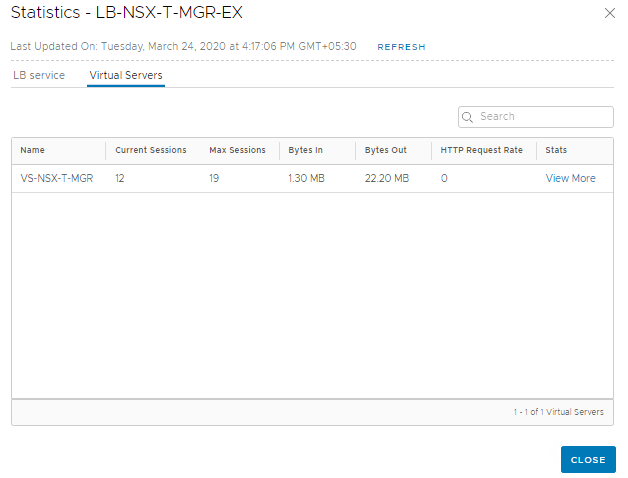
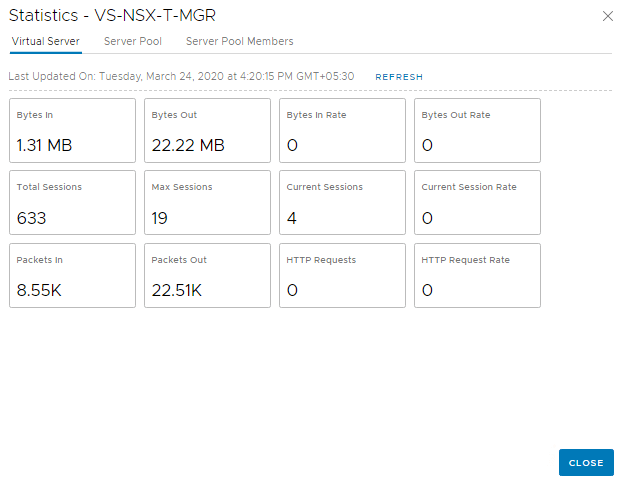
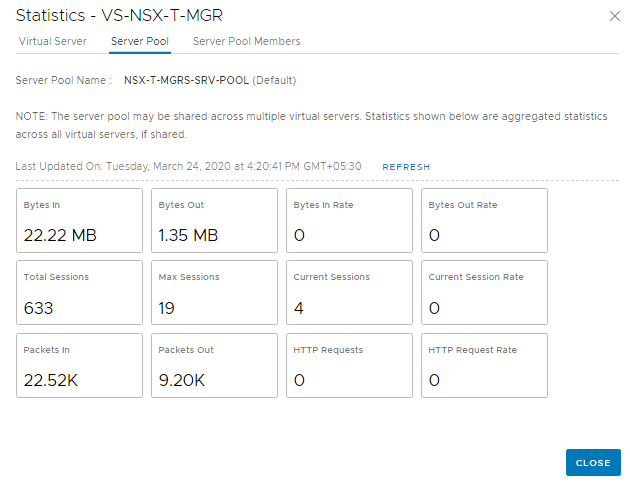
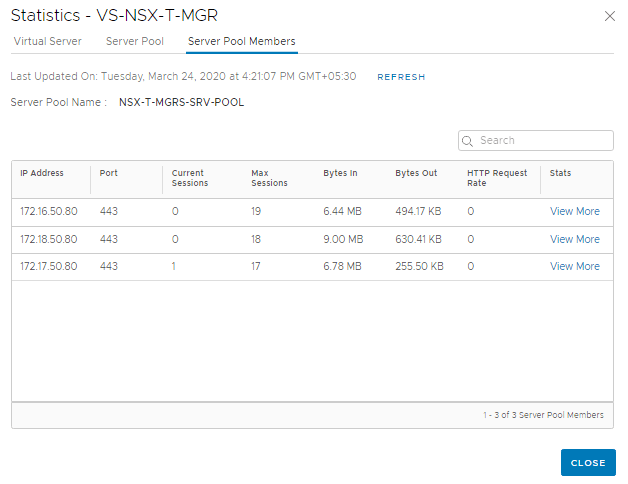
Since we have Source IP persistence in place, sending a request with a different Source IP should route it to another NSX-T Manager instance in the Server Pool. This can be easily achieved by using a Chrome Extension (or trying from a different client machine)

Let’s also try a debugger to see if there are any broken pages while getting reverse-proxied through the NSX-T Loadbalancer.
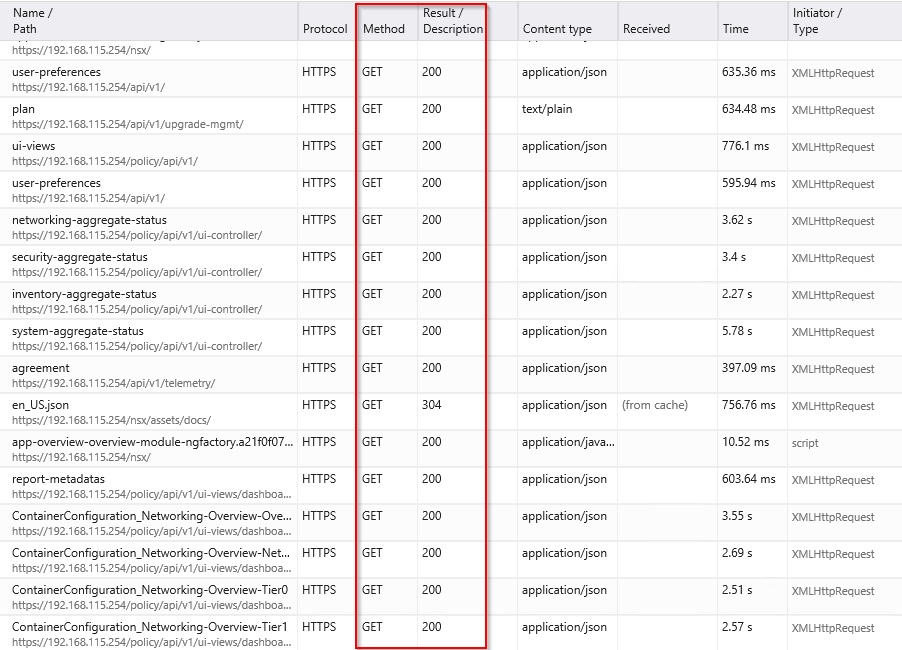
All GOOD!!!
Simulating a Rack Failure
Let’s bring down all the nodes on Rack 2. We should
- Loose all the Management VMs that are on VLAN backed Logical Segments (vCenter-Passive, RGNSXMGR02, and Edge02).
- Compute VMs on Overlay should vMotion to next rack without lose of connectivity as they are on NSX-T Overlay Segment.
- Loadbalacer VS Health Monitor should miss a poll to RGNSXMGR02 and should take it offline after the dead timer (5 sec)
- VS still has a quorum, so we should be able to access the NSX-T Management cluster.
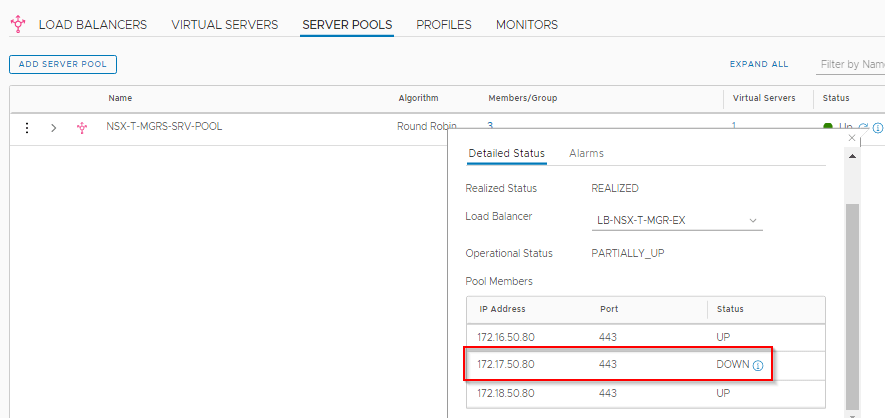
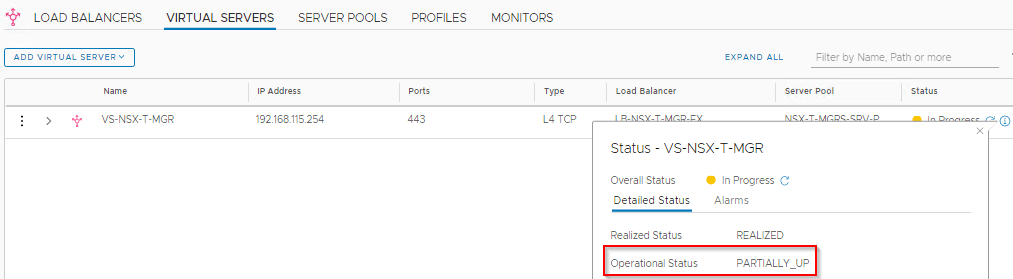
Once the failed Rack comes back online and that the Health Monitor has successfully polled RGNSXMGR02, it should dynamically add it back to the cluster.
We are now done with Part 2 and this concludes the blog series.
I hope this was informative. Thanks for reading
Continue reading? Here is the Part 1
https://vxplanet.com/2020/03/26/using-nsx-t-loadbalancer-for-the-nsx-t-management-cluster-part-1/

A very useful post Thanks!!
Thanks Avsa